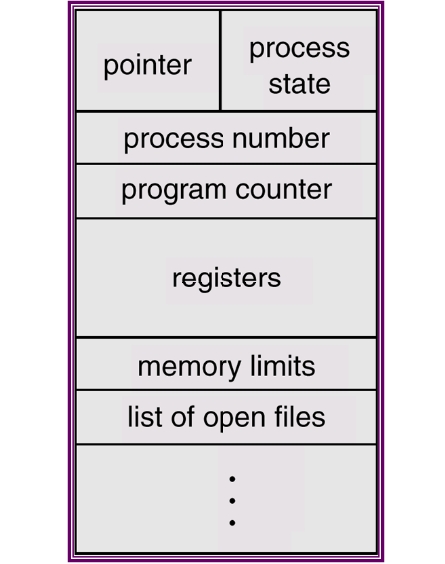
บทที่ 6 การจัดการไฟล์ (File Management)
บทที่ 6 การจัดการไฟล์ (File Management)
การจัดการไฟล์ (File Management)
•การทำงานในระบบคอมพิวเตอร์ทั้งหมดจำเป็นต้องมีการเก็บและนำ ข้อมูลไปใช้งาน
• ขณะที่โปรเซสกำลังทำงานข้อมูลจะเก็บไว้ในหน่วยความจำ ถ้าเครื่องคอมพิวเตอร์ดับไม่ว่าด้วยสาเหตุใดก็ตามข้อมูลทั้งหมดจะสูญหายไป
• ดังนั้นจึงจำเป็นต้องจัดเก็บข้อมูลเหล่านี้ไว้ในหน่วยจัดเก็บข้อมูลสำรอง ซึ่งอาจจะเป็นแผ่นดิสก์เก็ต ฮาร์ดดิสก์ หรืออุปกรณ์อื่น ๆ
• ในการจัดเก็บข้อมูลเหล่านี้มีจุดประสงค์เพื่อนำมาใช้งานต่อไป จึงจำเป็นต้องมีการกำหนดชื่อเพื่อแทนกลุ่มข้อมูล ซึ่งเราเรียกว่าไฟล์ข้อมูล
• นอกจากนี้ถ้าเราจัดเก็บข้อมูลไม่เป็นระเบียบจะทำให้การค้นหาไฟล์ข้อมูลที่ต้องการได้ยากหรือช้า ดังนั้นถ้าเราจัดหมวดหมู่ให้กับไฟล์ข้อมูลก็จะทำให้การค้นหาไฟล์ทำได้สะดวกหรือรวดเร็วขึ้น
• การจัดให้ไฟล์เป็นหมวดหมู่ก็คือการจัดเก็บในไดเร็กทอรี่ (Directory) หรือโฟลเดอร์ (Folder)
• หมายถึงสิ่งที่บรรจุข้อมูลต่าง ๆ ไว้ในที่เดียวกัน ซึ่งอาจหมายถึงโปรแกรมหรือข้อมูลที่เราต้องการเก็บไว้ด้วยกัน
• เมื่อเราต้องการค้นหาไฟล์ เราอ้างอิงด้วยชื่อไฟล์โดยไม่จำเป็นต้องทราบว่าไฟล์นั้นถูกเก็บไว้ในส่วนใดในดิสก์
• OS จะมีโปรแกรมย่อยที่ชื่อ System Call ทำหน้าที่จัดการงานที่เกี่ยวข้องกับไฟล์ เช่น การสร้างไฟล์ การลบไฟล์ การอ่าน/เขียนทับไฟล์
• DIR (DIRECTORY) ดูชื่อแฟ้มข้อมูล, เนื้อที่บนแผ่นดิสก์, ชื่อแผ่นดิสก์
• TYPE แสดงเนื้อหาหรือข้อมูลในแฟ้มข้อมูลที่กำหนด
• COPY ใช้คัดลอกแฟ้มข้อมูลหนึ่ง หรือหลายแฟ้มข้อมูลจากแฟ้มข้อมูลต้นทาง ไปยังแฟ้มข้อมูลปลายทาง
• REN (RENAME) เปลี่ยนชื่อแฟ้มข้อมูล (ข้อมูลข้างในแฟ้มข้อมูลยังเหมือนเดิม)
• DEL (DELETE) ลบแฟ้มข้อมูลออกจากแผ่นดิสก์
• MD (MAKE DIRECTORY) สร้าง subdirectory (ห้องย่อย) เพื่อจัดเก็บแฟ้มข้อมูล
• CD (CHANGE DIRECTORY) เป็นคำสั่งในการเปลี่ยนไปใช้งาน subdirectory ที่ต้องการ
• RD (REMOVE DIRECTORY) ลบ subdirectory (ห้องย่อย) ที่สร้างด้วยคำสั่ง MD
• TREE แสดงรายชื่อ directory ทั้งหมดในแผ่นดิสก์ ที่กำหนด
• SYS (SYSTEM) เป็นคำสั่ง copy แฟ้มข้อมูลที่ใช้ในการเปิดเครื่องลงในแผ่นดิสก์หรือฮาร์ดดิสก์ ที่ไม่มีระบบ
• DISKCOPY (COPY DISKETTE) เป็นคำสั่งที่ใช้ copy file ทั้งหมดจากแผ่นดิสก์จากแผ่นหนึ่งไปใส่อีกแผ่นหนึ่ง แต่ถ้าแผ่นดิสก์อีกแผ่น ยังไม่ได้ทำการ format ก็จะทำการ format ให้โดยอัตโนมัติ
• $ ls [-altCF] [directory …] เป็นการแสดงชื่อไฟล์ที่มีอยู่ใน ไดเรกทอรี่ที่ระบุ
• $ pwd คือคำสั่งที่ใช้เช็คว่าไดเรกทอรี่ปัจจุบันอยู่ที่ตำแหน่งใด
• $ cd [ชื่อพาท] เป็นการเปลี่ยนไดเรกทอรี่ไป เป็นไดเรกทอรี่ที่ต้องการ
• $ mkdir [ชื่อไดเรกทอรี่] คือคำสั่งที่ใช้ในการสร้างไดเรกทอรี่ใหม่ขึ้น
• $ rmdir [ชื่อไดเรกทอรี่] คือการลบไดเรกทอรี่ที่มีอยู่
• $ rm [ชื่อไฟล์] คือการลบไฟล์ที่อ้างถึง
• cat [ชื่อไฟล์] เป็นการแสดงข้อความในไฟล์ที่เป็นเท็กซ์ไฟล์ (Text Files : ไฟล์ตัวอักษร) แสดงบนจอภาพ
• $ mv [ชื่อไฟล์ต้นทาง] [ชื่อไฟล์ปลายทาง] คือการย้ายไฟล์ (move) จากพาทใดๆที่อ้างอิงถึงไปยังพาทปลายทาง
• $ more เป็นการแสดงข้อความในไฟล์ทีละหน้าจอแล้วหยุดรอจนกว่าผู้ใช้จะกดคีย์ช่องว่าง (space bar) จึงจะแสดงข้อมูลหน้า ถัดไปหรือกด Enter เพื่อแสดงข้อมูลบรรทัดถัดไปทีละบรรทัด
• $ cp [ชื่อไฟล์ต้นฉบับ] [ชื่อไฟล์สำเนา] เป็นคำสั่งคัดลอก (copy) ข้อมูลจากไฟล์หนึ่ง ไปยังปลายทางที่ต้องการ
• ในการกำหนดชื่อไฟล์ในแต่ละ OS นั้นมีความแตกต่างกันอยู่บ้าง
• แต่โดยหลักการจะคล้ายคลึงกันคือ ชื่อไฟล์จะประกอบ 2 ส่วนด้วยกัน คือส่วนที่เป็นชื่อหลัก และส่วนที่เป็นนามสกุล (File extension) ทั้งสองส่วนนี้จะถูกคั่นด้วยจุด (Period) เช่น readme.txt , document.doc เป็นต้น
• ตัวอย่างข้อกำหนดที่แตกต่างกันในแต่ละ OS
– ระบบ MS-DOS ส่วนที่เป็นชื่อหลักจะประกอบด้วยตัวอักษรไม่เกิน 8 ตัวอักษร และตามด้วยนามสกุลไม่เกิน 3 ตัวอักษร
– ระบบ UNIX ถือว่าการตั้งชื่อด้วยอักษรตัวใหญ่ตัวเล็กไม่เหมือนกัน (Case sensitive) เช่น Readme.txt , readme.txt หรือ README.TXT ถือว่าเป็นคนละไฟล์
ตัวอย่างชนิดของไฟล์ข้อมูล

– แบบไบต์เรียงต่อกันไป เช่น UNIX และ Windows เวลาอ่าน/เขียนก็จะทำงานทีละไบต์
– แบบเรกคอร์ด (Record) โดยมีขนาดของเรกคอร์ดคงที่ เช่น CP/M เวลาอ่าน/เขียนก็จะทำงานทีละเรกคอร์ด สำหรับเรกคอร์ดสุดท้ายอาจจะไม่เต็มเรกคอร์ดก็ได้
– แบบต้นไม้ (Tree) จะจัดเก็บเป็นบล็อก ในแต่ละบล็อกจะประกอบด้วยเรกคอร์ด โดยขนาดของแต่ละเรกคอร์ดอาจไม่เท่ากัน เช่น OS ในระบบ Mainframe เวลาอ่าน/เขียนก็จะทำงานโดยค้นไปตามการเชื่อมโยงของต้นไม้

• ไดเร็กทอรี เป็นไฟล์ประเภทหนึ่งซึ่งมีอยู่ 2 ระบบ
– ระบบไดเร็กทอรีเดี่ยว (Single-Level Directory Systems)
– ระบบไดเร็กทอรี 2 ระดับ (Two-Level Directory System)
• การจัดเก็บในลักษณะนี้ทำให้เกิดปัญหาดังนี้
– ไฟล์ต่าง ๆ ที่มีอยู่ในไดเร็กทอรีไม่สามารถแยกเจ้าของไฟล์ได้
– ไฟล์หลากหลายชนิดต้องอยู่ปะปนกันทำให้ไม่สะดวกในการค้นหา
– ในกรณีที่ต้องการสร้างไฟล์ให้มีชื่อเหมือนที่มีอยู่ก่อนแล้วไม่สามารถทำได้ ซึ่งถ้าสร้างไฟล์ให้มีชื่อเดียวกับที่มีอยู่ก่อนนั้น จะทำให้ไฟล์เก่าถูกเขียนทับลงไปโดยไม่ได้ตั้งใจ ทำให้ข้อมูลสูญหายได้
• จะกำหนดให้ผู้ใช้แต่ละคนสามารถสร้างไดเร็กทอรีย่อยของตนได้เรียกว่า Sub-Directory หรือไดเร็กทอรีย่อย ในแต่ละสับไดเร็กทอรีจะอยู่ภายใต้ไดเร็กทอรีรากเดียวกัน (Root directory)
• ภายในสับไดเร็กทอรีผู้ใช้สามารถกำหนดชื่อไฟล์ได้ตามใจโดยไม่ต้องไปกังวลว่าจะไปซ้ำกับชื่อใคร
• แต่ปัญหาก็คือ กรณีที่ผู้ใช้มีไฟล์หลายประเภทจะไม่สามาถแยกประเภทของไฟล์ต่าง ๆ ได้ตามต้องการ
•ระบบไฟล์ในปัจจุบันใช้โครงสร้างไดเร็กทอรีแบบนี้
•เรียกอีกชื่อหนึ่งว่า ระบบไดเร็กทอรีแบบโครงสร้างต้นไม้ (Tree Structure)

• ในการกำหนดที่อยู่หรือเส้นทางที่จะเข้าถึงไฟล์นั้น ๆ เรียกว่า พาธ (Path)
• ดังนั้นถ้าต้องการอ้างถึงไฟล์ใด ๆ ในดิสก์จำเป็นต้องระบุพาธให้ถูกต้องพร้อมชื่อไฟล์
• ตัวอย่างการอ้างถึงไฟล์ชื่อ Readme.doc ที่อยู่ภายใต้พาธ (Root user lib)
–Windows หรือ MS-DOS \user\lib\readme.doc
–UNIX หรือ Linux /user/lib/readme.doc

•ตัวอย่างการอ้างถึงไฟล์ชื่อ Readme.doc ที่อยู่ภายใต้พาธ (Root user lib) โดยที่ไดเร็กทอรีปัจจุบันอยู่ที่ user
–Windows หรือ MS-DOS \lib\readme.doc
–UNIX หรือ Linux /lib/readme.doc
–ภายในดิสก์สามารถแบ่งออกเป็นพาร์ติชัน (Partition) ในการเก็บข้อมูล และแต่ละพาร์ติชั่นมีความเป็นอิสระต่อกัน ทั้งยังสามารถกำหนดให้แต่ละพาร์ติชั่นมี OS ที่ต่างกันได้
–ภายในดิสก์จะถูกแบ่งออกเป็นเซกเตอร์ (Sector) เริ่มต้นจาก เซกเตอร์ 0 ซึ่งถือว่าเป็น Master boot record (MBR) ที่เก็บค่าเริ่มต้นของ OS สำหรับการบูตเครื่องเมื่อเริ่มใช้งาน ตอนท้ายของเซกเตอร์นี้จะเก็บตารางพาร์ติชั่นซึ่งระบุว่าในแต่ละพาร์ติชั่นมีแอดเดรสเริ่มต้นและสิ้นสุดที่ใด
–การจัดเก็บข้อมูลแบบต่อเนื่อง (Contiguous allocation)
–การจัดเก็บข้อมูลแบบลิงค์ลิสต์ (Link List allocation)
–ไอโหนด (I-nodes หรือ Index nodes)
•เป็นวิธีการจัดเก็บข้อมูลของไฟล์แบบง่ายที่สุด แต่ละไฟล์จะถูกแบ่งออกเป็นบล็อค แต่ละบล็อกมีขนาดเท่ากัน และจะถูกเก็บลงบนดิสก์อย่างต่อเนื่องทั้งไฟล์
•เหมาะสำหรับสื่อที่มีการจัดเก็บข้อมูลเพียงครั้งเดียว (Read Only Memory) เช่น CD-Rom เป็นต้น
• กรณีมีการแก้ไขข้อมูลเดิม แล้วการแก้ไขทำให้ขนาดของไฟล์มีขนาดใหญ่ขึ้น จึงจำเป็นต้องย้ายไฟล์ไปยังพื้นที่ใหม่ที่มีขนาดใหญ่พอที่จะบรรจุไฟล์ที่แก้ไขแล้ว ซึ่งการทำแบบนี้จะทำให้ต้องเสียเวลาเพิ่มขึ้นในการหาพื้นที่ใหม่
• ถ้าเกิดเหตุการณ์ในข้อแรกบ่อย ๆ อาจทำให้เกิดเนื้อที่ว่างมากมายระหว่างไฟล์ข้อมูลบนดิสก์ เมื่อมีการเก็บข้อมูลจนเต็มดิสก์จะทำให้เกิดปัญหาสำหรับไฟล์ขนาดใหญ่ไม่สามารถหาเนื้อที่ว่างในการเก็บข้อมูลได้ แม้จะมีเนื้อที่ว่างมากพอ แต่ไม่สามารถเรียกใช้ได้เพราะเนื้อที่เหล่านั้นกระจัดกระจายกันทั่วทั้งดิสก์
• วิธีการจัดเก็บแบบนี้ทำให้ไม่เสียเนื้อที่ว่างภายในดิสก์ แต่ยังมีเนื้อที่ว่างภายในบล็อกสำหรับบล็อกสุดท้ายของไฟล์ข้อมูล
• ข้อเสียของวิธีการนี้คือ
–เสียเวลาในการค้นหาข้อมูลของไฟล์มากกว่าแบบต่อเนื่อง เนื่องจากแต่ละบล็อกอยู่กระจัดกระจายไปทั่วดิสก์
–เสียเนื้อที่ไปกับพอยต์เตอร์ที่ทำหน้าที่ชี้ไปยังบล็อกต่าง ๆ
•I-node จะเก็บข้อมูลต่าง ๆ ที่เกี่ยวข้องกับไฟล์ไว้
•นอกจากนั้นยังมีหมายเลขบล็อกแบบลิงค์ลิสต์ 4 แบบดังนี้
–Direct Block ขนาด 10 หมายเลข เก็บจำนวนบล็อกไว้ได้ 10 หมายเลข
–Single indirect ขนาด 1 หมายเลข เก็บจำนวนบล็อกไว้ได้ 256 หมายเลข
–Double indirect ขนาด 1 หมายเลข เก็บจำนวนบล็อกไว้ได้ 256*256 หมายเลข
–Triple indirect ขนาด 1 หมายเลขเก็บจำนวนบล็อกไว้ได้ 256*256*256 หมายเลข
•ผู้ใช้ที่ต้องการจะเข้าถึงไฟล์ข้อมูลใด ๆ ก็จำเป็นต้องต้องทราบว่าไฟล์นั้น ๆ อยู่ในไดเร็กทอรี่ใด และจะเข้าถึงได้จากเส้นทาง (Path) ใด
•ดังนั้นไดเร็กทอรี่จำเป็นต้องมีตารางบันทึกไฟล์ต่าง ๆ ไว้
•โครงสร้างไดเร็กทอรี่ที่ใช้ใน DOS ภายในตารางจะมีองค์ประกอบดังนี้
•ตารางไดเร็กทอรี่ในระบบ DOS มีชื่อเรียกว่า FAT-32
•เนื่องจากในระบบ DOS การตั้งชื่อไฟล์ไม่สามารถตั้งชื่อได้เกิน 8 ตัวอักษร เนื่องจากข้อจำกัดในโครงสร้างของไดเร็กทอรี่
•การทำให้ระบบสามารถกำหนดชื่อไฟล์ได้มากกว่า 8 ตัวอักษรเราเรียกไฟล์ที่มีชื่อยาวกว่า 8 ตัวอักษรว่า “Long File Name”
•บริษัทไมโครซอฟต์จึงได้พิจารณาหาทางออกให้สามารถตั้งชื่อไฟล์ที่มีขนาดเกิน 8 ตัวอักษร โดยมีวิธีการดังนี้
•ปรับรูปแบบของตารางไดเร็กทอรี่ดังรูป

–Sequence มีขนาด 1 Byte แต่ใช้เพียง 6 บิต สามารถแสดงลำดับที่ได้ 64 (26) ตำแหน่ง ดังนั้นสามารถเก็บชื่อไฟล์ได้เท่ากับ 64*13=832 ตัวอักษร
–5 Characters of file name มีขนาด 10 Byte ใช้เก็บตัวอักษร 5 ตัวสลับกับช่องว่าง
–คุณสมบัติของไฟล์ มีขนาด 1 Byte
–6 Characters of file name มีขนาด 12 Byte ใช้เก็บตัวอักษร 6 ตัวสลับกับช่องว่าง
–2 Characters of file name มีขนาด 4 Byte ใช้เก็บตัวอักษร 2 ตัวสลับกับช่องว่าง
•นอกจากนั้นทุกไฟล์จะมีตารางแบบ DOS รวมอยู่ด้วยขนาด 32 Byte ต่อ 1 ไฟล์
ตัวอย่าง Long file name ที่ชื่อ “My Document No1.Doc


– เก็บเป็นไบต์ติดต่อกันไป
– เก็บเป็นบล็อค
• มีระบบกู้คืนข้อมูลได้
ปัญหาที่อาจเกิดขึ้น
• ไฟดับ อาจทำให้การเก็บข้อมูลสูญหายได้
การแก้ปัญหา
• ในระบบ windows จะมีการ scan disk ทุกครั้งที่ไม่มีการ shut down เครื่อง
• ในระบบ Linux, Unix จะมีการตรวจสอบไฟล์ที่เป็น i-node ตอนที่เปิดเครื่อง
เช่นเดียวกันกับ windows
• Linux จะมีระบบไฟล์ที่เรียกว่า Ext3 ซึ่งจะป้องกันปัญหานี้ได้ดี
• สำรองเฉพาะที่มีการเปลี่ยนแปลง
•การใช้แคช (Caching)
•การอ่านบล็อกข้อมูลไว้ล่วงหน้า (Block Read Ahead)
•การลดการเคลื่อนที่ของหัวอ่าน (Reducing Disk Arm Motion)
•Log-Structure file System
•ระบบการจัดการฐานข้อมูลหรือ DBMS (database Management System) ช่วยให้ผู้ใช้เข้าถึงได้ง่ายสะดวกและมีประสิทธิภาพ
ระบบการจัดการฐานข้อมูลหรือ DBMS

•รักษาความถูกต้องของข้อมูล
•แบ่งปันกันใช้ได้
•การป้องกันและรักษาความปลอดภัยให้กับข้อมูลทำได้สะดวก
•ความเป็นอิสระของข้อมูล
•ภาษาจัดการข้อมูลหรือ DML (Data Manipulation Language) เป็นภาษาที่ผู้ใช้ใช้จัดการกับข้อมูลของผู้ใช้เอง เช่น Select, Delete
–กำหนดโครงสร้างหรือรูปแบบของฐานข้อมูล
–กำหนดโครงสร้างของอุปกรณ์เก็บข้อมูลและวิธีเข้าถึง
–มอบหมายขอบเขตอำนาจหน้าที่ของการเข้าถึงของผู้ใช้

•ฐานข้อมูลแบบเครือข่าย (Network Database Model)
•ฐานข้อมูลแบบความสัมพันธ์ (Relational Database Model)



ระบบฐานข้อมูลและ OS
•DBMS จะทำงานซ้อนอยู่บนระบบไฟล์
•การเข้าถึงข้อมูลในฐานข้อมูลของ DBMS จะต้องเรียกใช้ รูทีนต่าง ๆ ในระบบไฟล์

•การทำงานในระบบคอมพิวเตอร์ทั้งหมดจำเป็นต้องมีการเก็บและนำ ข้อมูลไปใช้งาน
• ขณะที่โปรเซสกำลังทำงานข้อมูลจะเก็บไว้ในหน่วยความจำ ถ้าเครื่องคอมพิวเตอร์ดับไม่ว่าด้วยสาเหตุใดก็ตามข้อมูลทั้งหมดจะสูญหายไป
• ดังนั้นจึงจำเป็นต้องจัดเก็บข้อมูลเหล่านี้ไว้ในหน่วยจัดเก็บข้อมูลสำรอง ซึ่งอาจจะเป็นแผ่นดิสก์เก็ต ฮาร์ดดิสก์ หรืออุปกรณ์อื่น ๆ
• ในการจัดเก็บข้อมูลเหล่านี้มีจุดประสงค์เพื่อนำมาใช้งานต่อไป จึงจำเป็นต้องมีการกำหนดชื่อเพื่อแทนกลุ่มข้อมูล ซึ่งเราเรียกว่าไฟล์ข้อมูล
• นอกจากนี้ถ้าเราจัดเก็บข้อมูลไม่เป็นระเบียบจะทำให้การค้นหาไฟล์ข้อมูลที่ต้องการได้ยากหรือช้า ดังนั้นถ้าเราจัดหมวดหมู่ให้กับไฟล์ข้อมูลก็จะทำให้การค้นหาไฟล์ทำได้สะดวกหรือรวดเร็วขึ้น
• การจัดให้ไฟล์เป็นหมวดหมู่ก็คือการจัดเก็บในไดเร็กทอรี่ (Directory) หรือโฟลเดอร์ (Folder)
ไฟล์ข้อมูล (File)
• หมายถึงสิ่งที่บรรจุข้อมูลต่าง ๆ ไว้ในที่เดียวกัน ซึ่งอาจหมายถึงโปรแกรมหรือข้อมูลที่เราต้องการเก็บไว้ด้วยกัน• เมื่อเราต้องการค้นหาไฟล์ เราอ้างอิงด้วยชื่อไฟล์โดยไม่จำเป็นต้องทราบว่าไฟล์นั้นถูกเก็บไว้ในส่วนใดในดิสก์
• OS จะมีโปรแกรมย่อยที่ชื่อ System Call ทำหน้าที่จัดการงานที่เกี่ยวข้องกับไฟล์ เช่น การสร้างไฟล์ การลบไฟล์ การอ่าน/เขียนทับไฟล์
คำสั่งที่ใช้ในการจัดการไฟล์
• DIR (DIRECTORY) ดูชื่อแฟ้มข้อมูล, เนื้อที่บนแผ่นดิสก์, ชื่อแผ่นดิสก์ • TYPE แสดงเนื้อหาหรือข้อมูลในแฟ้มข้อมูลที่กำหนด
• COPY ใช้คัดลอกแฟ้มข้อมูลหนึ่ง หรือหลายแฟ้มข้อมูลจากแฟ้มข้อมูลต้นทาง ไปยังแฟ้มข้อมูลปลายทาง
• REN (RENAME) เปลี่ยนชื่อแฟ้มข้อมูล (ข้อมูลข้างในแฟ้มข้อมูลยังเหมือนเดิม)
• DEL (DELETE) ลบแฟ้มข้อมูลออกจากแผ่นดิสก์
• MD (MAKE DIRECTORY) สร้าง subdirectory (ห้องย่อย) เพื่อจัดเก็บแฟ้มข้อมูล
• CD (CHANGE DIRECTORY) เป็นคำสั่งในการเปลี่ยนไปใช้งาน subdirectory ที่ต้องการ
• RD (REMOVE DIRECTORY) ลบ subdirectory (ห้องย่อย) ที่สร้างด้วยคำสั่ง MD
• TREE แสดงรายชื่อ directory ทั้งหมดในแผ่นดิสก์ ที่กำหนด
• SYS (SYSTEM) เป็นคำสั่ง copy แฟ้มข้อมูลที่ใช้ในการเปิดเครื่องลงในแผ่นดิสก์หรือฮาร์ดดิสก์ ที่ไม่มีระบบ
• DISKCOPY (COPY DISKETTE) เป็นคำสั่งที่ใช้ copy file ทั้งหมดจากแผ่นดิสก์จากแผ่นหนึ่งไปใส่อีกแผ่นหนึ่ง แต่ถ้าแผ่นดิสก์อีกแผ่น ยังไม่ได้ทำการ format ก็จะทำการ format ให้โดยอัตโนมัติ
• $ ls [-altCF] [directory …] เป็นการแสดงชื่อไฟล์ที่มีอยู่ใน ไดเรกทอรี่ที่ระบุ
• $ pwd คือคำสั่งที่ใช้เช็คว่าไดเรกทอรี่ปัจจุบันอยู่ที่ตำแหน่งใด
• $ cd [ชื่อพาท] เป็นการเปลี่ยนไดเรกทอรี่ไป เป็นไดเรกทอรี่ที่ต้องการ
• $ mkdir [ชื่อไดเรกทอรี่] คือคำสั่งที่ใช้ในการสร้างไดเรกทอรี่ใหม่ขึ้น
• $ rmdir [ชื่อไดเรกทอรี่] คือการลบไดเรกทอรี่ที่มีอยู่
• $ rm [ชื่อไฟล์] คือการลบไฟล์ที่อ้างถึง
• cat [ชื่อไฟล์] เป็นการแสดงข้อความในไฟล์ที่เป็นเท็กซ์ไฟล์ (Text Files : ไฟล์ตัวอักษร) แสดงบนจอภาพ
• $ mv [ชื่อไฟล์ต้นทาง] [ชื่อไฟล์ปลายทาง] คือการย้ายไฟล์ (move) จากพาทใดๆที่อ้างอิงถึงไปยังพาทปลายทาง
• $ more เป็นการแสดงข้อความในไฟล์ทีละหน้าจอแล้วหยุดรอจนกว่าผู้ใช้จะกดคีย์ช่องว่าง (space bar) จึงจะแสดงข้อมูลหน้า ถัดไปหรือกด Enter เพื่อแสดงข้อมูลบรรทัดถัดไปทีละบรรทัด
• $ cp [ชื่อไฟล์ต้นฉบับ] [ชื่อไฟล์สำเนา] เป็นคำสั่งคัดลอก (copy) ข้อมูลจากไฟล์หนึ่ง ไปยังปลายทางที่ต้องการ
การตั้งชื่อไฟล์ข้อมูล
• ในการกำหนดชื่อไฟล์ในแต่ละ OS นั้นมีความแตกต่างกันอยู่บ้าง • แต่โดยหลักการจะคล้ายคลึงกันคือ ชื่อไฟล์จะประกอบ 2 ส่วนด้วยกัน คือส่วนที่เป็นชื่อหลัก และส่วนที่เป็นนามสกุล (File extension) ทั้งสองส่วนนี้จะถูกคั่นด้วยจุด (Period) เช่น readme.txt , document.doc เป็นต้น
• ตัวอย่างข้อกำหนดที่แตกต่างกันในแต่ละ OS
– ระบบ MS-DOS ส่วนที่เป็นชื่อหลักจะประกอบด้วยตัวอักษรไม่เกิน 8 ตัวอักษร และตามด้วยนามสกุลไม่เกิน 3 ตัวอักษร
– ระบบ UNIX ถือว่าการตั้งชื่อด้วยอักษรตัวใหญ่ตัวเล็กไม่เหมือนกัน (Case sensitive) เช่น Readme.txt , readme.txt หรือ README.TXT ถือว่าเป็นคนละไฟล์
ตัวอย่างชนิดของไฟล์ข้อมูล

โครงสร้างไฟล์ข้อมูล
• การจัดโครงสร้างไฟล์ข้อมูลที่ใช้กันอยู่ทั่วไปมีอยู่ 3 แบบ– แบบไบต์เรียงต่อกันไป เช่น UNIX และ Windows เวลาอ่าน/เขียนก็จะทำงานทีละไบต์
– แบบเรกคอร์ด (Record) โดยมีขนาดของเรกคอร์ดคงที่ เช่น CP/M เวลาอ่าน/เขียนก็จะทำงานทีละเรกคอร์ด สำหรับเรกคอร์ดสุดท้ายอาจจะไม่เต็มเรกคอร์ดก็ได้
– แบบต้นไม้ (Tree) จะจัดเก็บเป็นบล็อก ในแต่ละบล็อกจะประกอบด้วยเรกคอร์ด โดยขนาดของแต่ละเรกคอร์ดอาจไม่เท่ากัน เช่น OS ในระบบ Mainframe เวลาอ่าน/เขียนก็จะทำงานโดยค้นไปตามการเชื่อมโยงของต้นไม้

ไดเร็กทอรี (Directory)
• ไดเร็กทอรี (Directory) หมายถึงสารบัญที่เก็บรวบรวมรายชื่อของไฟล์ต่าง ๆ ทั้งหมดไว้ เพื่อให้ผู้ใช้สามารถค้นหา เรียกคืน และตรวจสอบข้อมูลที่ต้องการได้• ไดเร็กทอรี เป็นไฟล์ประเภทหนึ่งซึ่งมีอยู่ 2 ระบบ
– ระบบไดเร็กทอรีเดี่ยว (Single-Level Directory Systems)
– ระบบไดเร็กทอรี 2 ระดับ (Two-Level Directory System)
–ระบบไดเร็กทอรีหลายระดับ (Hierarchical Directory Systems)
• เป็นระบบที่มีโครงสร้างง่ายที่สุด ภายในระบบจะมีอยู่เพียงไดเร็กทอรีเดียว รวบรวมไฟล์ทุกไฟล์ไว้ที่เดียวกัน และทุกไฟล์จะอยู่ในระดับเดียวกัน• การจัดเก็บในลักษณะนี้ทำให้เกิดปัญหาดังนี้
– ไฟล์ต่าง ๆ ที่มีอยู่ในไดเร็กทอรีไม่สามารถแยกเจ้าของไฟล์ได้
– ไฟล์หลากหลายชนิดต้องอยู่ปะปนกันทำให้ไม่สะดวกในการค้นหา
– ในกรณีที่ต้องการสร้างไฟล์ให้มีชื่อเหมือนที่มีอยู่ก่อนแล้วไม่สามารถทำได้ ซึ่งถ้าสร้างไฟล์ให้มีชื่อเดียวกับที่มีอยู่ก่อนนั้น จะทำให้ไฟล์เก่าถูกเขียนทับลงไปโดยไม่ได้ตั้งใจ ทำให้ข้อมูลสูญหายได้
ระบบไดเร็กทอรี 2 ระดับ(Two-Level Directory System)
• แก้ปัญหาแบบแรกได้แต่ไม่เต็มร้อย• จะกำหนดให้ผู้ใช้แต่ละคนสามารถสร้างไดเร็กทอรีย่อยของตนได้เรียกว่า Sub-Directory หรือไดเร็กทอรีย่อย ในแต่ละสับไดเร็กทอรีจะอยู่ภายใต้ไดเร็กทอรีรากเดียวกัน (Root directory)
• ภายในสับไดเร็กทอรีผู้ใช้สามารถกำหนดชื่อไฟล์ได้ตามใจโดยไม่ต้องไปกังวลว่าจะไปซ้ำกับชื่อใคร
• แต่ปัญหาก็คือ กรณีที่ผู้ใช้มีไฟล์หลายประเภทจะไม่สามาถแยกประเภทของไฟล์ต่าง ๆ ได้ตามต้องการ
ระบบไดเร็กทอรีหลายระดับ ( Hierarchical Directory Systems )
•เพื่อแก้ปัญหาระบบไดเร็กทอรีเดี่ยว OS จึงยอมให้มีการสร้างโครงสร้างไดเร็กทอรีแบบหลายระดับขึ้นมา ซึ่งกำหนดให้ผู้ใช้แต่ละคนสามารถสร้างไดเร็กทอรีย่อย (Sub-directory) ได้โดยไม่จำกัด•ระบบไฟล์ในปัจจุบันใช้โครงสร้างไดเร็กทอรีแบบนี้
•เรียกอีกชื่อหนึ่งว่า ระบบไดเร็กทอรีแบบโครงสร้างต้นไม้ (Tree Structure)

ชื่อพาธ (Path name)
• การอ้างอิงถึงไฟล์ใด ๆ ก็ตามจำเป็นต้องระบุที่อยู่ของไฟล์นั้น ๆ ให้ถูกต้องว่าอยู่ในไดเร็กทอรีใด หรือสับไดเร็กทอรีใด• ในการกำหนดที่อยู่หรือเส้นทางที่จะเข้าถึงไฟล์นั้น ๆ เรียกว่า พาธ (Path)
• ดังนั้นถ้าต้องการอ้างถึงไฟล์ใด ๆ ในดิสก์จำเป็นต้องระบุพาธให้ถูกต้องพร้อมชื่อไฟล์
–การอ้างชื่อไฟล์แบบสัมบูรณ์ (Absolute path name)
• เป็นการอ้างถึงไฟล์โดยเริ่มจากราก (Root) เสมอตามด้วยชื่อสับไดเร็กทอรีย่อยไล่ลงมาตามลำดับชั้นของไดเร็กทอรีจนกระทั่งถึงไดเร็กทอรีที่บรรจุไฟล์อยู่ และจบลงด้วยชื่อไฟล์นั้น ๆ• ตัวอย่างการอ้างถึงไฟล์ชื่อ Readme.doc ที่อยู่ภายใต้พาธ (Root user lib)
–Windows หรือ MS-DOS \user\lib\readme.doc
–UNIX หรือ Linux /user/lib/readme.doc

การอ้างชื่อไฟล์แบบสัมพัทธ์ (Relative path name)
•เป็นการอ้างถึงไฟล์โดยที่ผู้ใช้จะต้องเข้าใจในเรื่องระบบไดเร็กทอรีปัจจุบัน (Current directory) เนื่องจากการอ้างถึงชื่อไฟล์จะเริ่มต้นจากไดเร็กทอรีปัจจุบันแล้วไล่ไปตามลำดับชั้นของไดเร็กทอรีที่ไฟล์นั้นอยู่และจบลงด้วยชื่อไฟล์นั้น•ตัวอย่างการอ้างถึงไฟล์ชื่อ Readme.doc ที่อยู่ภายใต้พาธ (Root user lib) โดยที่ไดเร็กทอรีปัจจุบันอยู่ที่ user
–Windows หรือ MS-DOS \lib\readme.doc
–UNIX หรือ Linux /lib/readme.doc
การทำงานของระบบไฟล์ (File system Implementation)
•โครงสร้างของระบบไฟล์ (File system layout)–ภายในดิสก์สามารถแบ่งออกเป็นพาร์ติชัน (Partition) ในการเก็บข้อมูล และแต่ละพาร์ติชั่นมีความเป็นอิสระต่อกัน ทั้งยังสามารถกำหนดให้แต่ละพาร์ติชั่นมี OS ที่ต่างกันได้
–ภายในดิสก์จะถูกแบ่งออกเป็นเซกเตอร์ (Sector) เริ่มต้นจาก เซกเตอร์ 0 ซึ่งถือว่าเป็น Master boot record (MBR) ที่เก็บค่าเริ่มต้นของ OS สำหรับการบูตเครื่องเมื่อเริ่มใช้งาน ตอนท้ายของเซกเตอร์นี้จะเก็บตารางพาร์ติชั่นซึ่งระบุว่าในแต่ละพาร์ติชั่นมีแอดเดรสเริ่มต้นและสิ้นสุดที่ใด
วิธีจัดเก็บข้อมูลของไฟล์ (Implementation File)
•วิธีการจัดเก็บข้อมูลลงบนสื่อจัดเก็บข้อมูลแบ่งออกเป็น 3 แบบ–การจัดเก็บข้อมูลแบบต่อเนื่อง (Contiguous allocation)
–การจัดเก็บข้อมูลแบบลิงค์ลิสต์ (Link List allocation)
–ไอโหนด (I-nodes หรือ Index nodes)
การจัดเก็บข้อมูลแบบต่อเนื่อง (Contiguous allocation)
•เป็นวิธีการจัดเก็บข้อมูลของไฟล์แบบง่ายที่สุด แต่ละไฟล์จะถูกแบ่งออกเป็นบล็อค แต่ละบล็อกมีขนาดเท่ากัน และจะถูกเก็บลงบนดิสก์อย่างต่อเนื่องทั้งไฟล์
ข้อดีในจัดเก็บข้อมูลแบบต่อเนื่อง
•สามารถสร้างประสิทธิภาพได้สูงสุดในการค้นหาข้อมูล เนื่องจากการจัดเก็บบล็อกข้อมูลเรียงต่อเนื่องจึงไม่เสียเวลาในการค้นหาบล็อกทุก ๆ บล็อก เพียงแต่หาบล็อกแรกพบก็สามารถอ่านข้อมูลได้ทั้งไฟล์•เหมาะสำหรับสื่อที่มีการจัดเก็บข้อมูลเพียงครั้งเดียว (Read Only Memory) เช่น CD-Rom เป็นต้น
ข้อเสียในจัดเก็บข้อมูลแบบต่อเนื่อง
• กรณีมีการแก้ไขข้อมูลเดิม แล้วการแก้ไขทำให้ขนาดของไฟล์มีขนาดใหญ่ขึ้น จึงจำเป็นต้องย้ายไฟล์ไปยังพื้นที่ใหม่ที่มีขนาดใหญ่พอที่จะบรรจุไฟล์ที่แก้ไขแล้ว ซึ่งการทำแบบนี้จะทำให้ต้องเสียเวลาเพิ่มขึ้นในการหาพื้นที่ใหม่
• ถ้าเกิดเหตุการณ์ในข้อแรกบ่อย ๆ อาจทำให้เกิดเนื้อที่ว่างมากมายระหว่างไฟล์ข้อมูลบนดิสก์ เมื่อมีการเก็บข้อมูลจนเต็มดิสก์จะทำให้เกิดปัญหาสำหรับไฟล์ขนาดใหญ่ไม่สามารถหาเนื้อที่ว่างในการเก็บข้อมูลได้ แม้จะมีเนื้อที่ว่างมากพอ แต่ไม่สามารถเรียกใช้ได้เพราะเนื้อที่เหล่านั้นกระจัดกระจายกันทั่วทั้งดิสก์
การจัดเก็บข้อมูลแบบลิงค์ลิสต์ (Link List allocation)
• วิธีนี้มีการแบ่งไฟล์ออกเป็นบล็อก ๆ เช่นเดียวกัน แต่การจัดเก็บเนื้อที่ของแต่ละบล็อกจะไม่ต่อเนื่องกัน แต่ละบล็อกจะถูกเชื่อมโยงกันด้วยพอยต์เตอร์ ตั้งแต่บล็อกแรกจนถึงบล็อกสุดท้ายของไฟล์ข้อมูลนั้น ๆ• วิธีการจัดเก็บแบบนี้ทำให้ไม่เสียเนื้อที่ว่างภายในดิสก์ แต่ยังมีเนื้อที่ว่างภายในบล็อกสำหรับบล็อกสุดท้ายของไฟล์ข้อมูล
• ข้อเสียของวิธีการนี้คือ
–เสียเวลาในการค้นหาข้อมูลของไฟล์มากกว่าแบบต่อเนื่อง เนื่องจากแต่ละบล็อกอยู่กระจัดกระจายไปทั่วดิสก์
–เสียเนื้อที่ไปกับพอยต์เตอร์ที่ทำหน้าที่ชี้ไปยังบล็อกต่าง ๆ
ไอโหนด (I-nodes หรือ Index nodes)
•เป็นวิธีการที่ใช้กันใน UNIX โดยจะมีการสร้างตารางเล็กที่เรียกว่า I-nodeให้กับแต่ละไฟล์•I-node จะเก็บข้อมูลต่าง ๆ ที่เกี่ยวข้องกับไฟล์ไว้
•นอกจากนั้นยังมีหมายเลขบล็อกแบบลิงค์ลิสต์ 4 แบบดังนี้
–Direct Block ขนาด 10 หมายเลข เก็บจำนวนบล็อกไว้ได้ 10 หมายเลข
–Single indirect ขนาด 1 หมายเลข เก็บจำนวนบล็อกไว้ได้ 256 หมายเลข
–Double indirect ขนาด 1 หมายเลข เก็บจำนวนบล็อกไว้ได้ 256*256 หมายเลข
–Triple indirect ขนาด 1 หมายเลขเก็บจำนวนบล็อกไว้ได้ 256*256*256 หมายเลข
โครงสร้างไดเร็กทอรี่ (Directory Structure) ใน DOS
•ไดเร็กทอรี่เป็นที่เก็บรวบรวมไฟล์ข้อมูลต่าง ๆ เข้าไว้ด้วยกัน•ผู้ใช้ที่ต้องการจะเข้าถึงไฟล์ข้อมูลใด ๆ ก็จำเป็นต้องต้องทราบว่าไฟล์นั้น ๆ อยู่ในไดเร็กทอรี่ใด และจะเข้าถึงได้จากเส้นทาง (Path) ใด
•ดังนั้นไดเร็กทอรี่จำเป็นต้องมีตารางบันทึกไฟล์ต่าง ๆ ไว้
•โครงสร้างไดเร็กทอรี่ที่ใช้ใน DOS ภายในตารางจะมีองค์ประกอบดังนี้
–ชื่อไฟล์ มีขนาด 8 Byte
–ส่วนขยาย มีขนาด 3 Byte
–คุณสมบัติของไฟล์ (File Attribute) มีขนาด 1 Byte
––กั้นไว้ มีขนาด 10 Byte
–วัน-เวลาที่บันทึก มีขนาด 4 Byte
–หมายเลขบล็อกแรกของไฟล์ มีขนาด 2 Byte
–ขนาดของไฟล์ มีขนาด 4 Byte
–

โครงสร้างไดเร็กทอรี่ในระบบ Windows
(Directory Structure of Windows)
–ส่วนขยาย มีขนาด 3 Byte
–คุณสมบัติของไฟล์ (File Attribute) มีขนาด 1 Byte
––กั้นไว้ มีขนาด 10 Byte
–วัน-เวลาที่บันทึก มีขนาด 4 Byte
–หมายเลขบล็อกแรกของไฟล์ มีขนาด 2 Byte
–ขนาดของไฟล์ มีขนาด 4 Byte
–

โครงสร้างไดเร็กทอรี่ในระบบ Windows
(Directory Structure of Windows)
•ตารางไดเร็กทอรี่ในระบบ DOS มีชื่อเรียกว่า FAT-32
•เนื่องจากในระบบ DOS การตั้งชื่อไฟล์ไม่สามารถตั้งชื่อได้เกิน 8 ตัวอักษร เนื่องจากข้อจำกัดในโครงสร้างของไดเร็กทอรี่
•การทำให้ระบบสามารถกำหนดชื่อไฟล์ได้มากกว่า 8 ตัวอักษรเราเรียกไฟล์ที่มีชื่อยาวกว่า 8 ตัวอักษรว่า “Long File Name”
•บริษัทไมโครซอฟต์จึงได้พิจารณาหาทางออกให้สามารถตั้งชื่อไฟล์ที่มีขนาดเกิน 8 ตัวอักษร โดยมีวิธีการดังนี้
•ปรับรูปแบบของตารางไดเร็กทอรี่ดังรูป

โครงสร้างไดเร็กทอรี่ในระบบ Windows
(Directory Structure of Windows)
•ในแต่ละฟิลด์ของตารางประกอบด้วยส่วนต่าง ๆ ดังนี้–Sequence มีขนาด 1 Byte แต่ใช้เพียง 6 บิต สามารถแสดงลำดับที่ได้ 64 (26) ตำแหน่ง ดังนั้นสามารถเก็บชื่อไฟล์ได้เท่ากับ 64*13=832 ตัวอักษร
–5 Characters of file name มีขนาด 10 Byte ใช้เก็บตัวอักษร 5 ตัวสลับกับช่องว่าง
–คุณสมบัติของไฟล์ มีขนาด 1 Byte
–6 Characters of file name มีขนาด 12 Byte ใช้เก็บตัวอักษร 6 ตัวสลับกับช่องว่าง
–2 Characters of file name มีขนาด 4 Byte ใช้เก็บตัวอักษร 2 ตัวสลับกับช่องว่าง
•นอกจากนั้นทุกไฟล์จะมีตารางแบบ DOS รวมอยู่ด้วยขนาด 32 Byte ต่อ 1 ไฟล์
ตัวอย่าง Long file name ที่ชื่อ “My Document No1.Doc

การใช้ไฟล์ร่วมกัน (Share files)

การจัดการเนื้อที่ว่างภายในดีสก์ (Disk space management)
•มีอยู่ 2 วิธีในการจัดเก็บ– เก็บเป็นไบต์ติดต่อกันไป
– เก็บเป็นบล็อค
ความน่าเชื่อถือของระบบไฟล์ (File system reliability)
•ข้อมูลมีความสำคัญมาก จำเป็นต้องเชื่อถือได้ว่าจะไม่เสียหาย• มีระบบกู้คืนข้อมูลได้
ปัญหาที่อาจเกิดขึ้น
• ไฟดับ อาจทำให้การเก็บข้อมูลสูญหายได้
การแก้ปัญหา
• ในระบบ windows จะมีการ scan disk ทุกครั้งที่ไม่มีการ shut down เครื่อง
• ในระบบ Linux, Unix จะมีการตรวจสอบไฟล์ที่เป็น i-node ตอนที่เปิดเครื่อง
เช่นเดียวกันกับ windows
• Linux จะมีระบบไฟล์ที่เรียกว่า Ext3 ซึ่งจะป้องกันปัญหานี้ได้ดี
การทำสำรองข้อมูล (Backups)
•สำรองทั้งหมดทุกครั้งที่มีการเปลี่ยนแปลง• สำรองเฉพาะที่มีการเปลี่ยนแปลง
ประสิทธิภาพของระบบไฟล์
(File System Performance)•การใช้แคช (Caching)
•การอ่านบล็อกข้อมูลไว้ล่วงหน้า (Block Read Ahead)
•การลดการเคลื่อนที่ของหัวอ่าน (Reducing Disk Arm Motion)
•Log-Structure file System
ระบบฐานข้อมูล (Database System)
•หมายถึงกลุ่มของข้อมูลที่ถูกรวบรวมไว้ เพื่อที่จะนำข้อมูลเหล่านี้มาใช้ภายหลัง•ระบบการจัดการฐานข้อมูลหรือ DBMS (database Management System) ช่วยให้ผู้ใช้เข้าถึงได้ง่ายสะดวกและมีประสิทธิภาพ
ระบบการจัดการฐานข้อมูลหรือ DBMS
(database Management System)

ข้อได้เปรียบของระบบฐานข้อมูล
•ลดการเก็บข้อมูลที่ซ้ำซ้อน•รักษาความถูกต้องของข้อมูล
•แบ่งปันกันใช้ได้
•การป้องกันและรักษาความปลอดภัยให้กับข้อมูลทำได้สะดวก
•ความเป็นอิสระของข้อมูล
ภาษาของระบบฐานข้อมูล
•ภาษากำหนดข้อมูลหรือ DDL (Data Definition Language) เป็นภาษาที่ผู้ใช้ได้กำหนดโครงสร้างหรือแบบแผนในการเก็บข้อมูล เช่น Create•ภาษาจัดการข้อมูลหรือ DML (Data Manipulation Language) เป็นภาษาที่ผู้ใช้ใช้จัดการกับข้อมูลของผู้ใช้เอง เช่น Select, Delete
ผู้บริหารฐานข้อมูล
•ผู้บริหารฐานข้อมูล (DBA: Database Administrator) มีหน้าที่–กำหนดโครงสร้างหรือรูปแบบของฐานข้อมูล
–กำหนดโครงสร้างของอุปกรณ์เก็บข้อมูลและวิธีเข้าถึง
–มอบหมายขอบเขตอำนาจหน้าที่ของการเข้าถึงของผู้ใช้
ความสัมพันธ์ของข้อมูล (Relationship)

รูปแบบของระบบฐานข้อมูล
•ฐานข้อมูลแบบลำดับชั้น (Hierarchical Database Model)•ฐานข้อมูลแบบเครือข่าย (Network Database Model)
•ฐานข้อมูลแบบความสัมพันธ์ (Relational Database Model)
ฐานข้อมูลแบบลำดับชั้น

ฐานข้อมูลแบบเครือข่าย

ฐานข้อมูลแบบความสัมพันธ์

ระบบฐานข้อมูลและ OS
•DBMS จะทำงานซ้อนอยู่บนระบบไฟล์
•การเข้าถึงข้อมูลในฐานข้อมูลของ DBMS จะต้องเรียกใช้ รูทีนต่าง ๆ ในระบบไฟล์

แหล่งที่มาของข้อมูล
- http://www.chantra.sru.ac.th/OS.html