บทที่ 3 การจัดเวลาซีพียู (CPU Scheduling)
การจัดการเวลา CPU
โดย นายอาทิตย์ ยลระบิล ชั้น ปวส.1 6031280069
การจัดเวลาซีพียู (CPU Scheduling)
การจัดเวลาซีพียู (CPU Scheduling) เป็นหลักการทำงานหนึ่งของโปรแกรมจัดการระบบที่มีความสามารถในการรันโปรแกรมหลาย ๆ โปรแกรมในเวลาเดียวกัน ซึ่งการแบ่งเวลาการเข้าใช้ซีพียูให้กับงานที่อาจถูกส่งเข้ามาหลาย ๆ งานพร้อม ๆ กัน ที่ซีพียูอาจมีจำนวนน้อยกว่าจำนวนโปรแกรม หรืออาจมีซีพียูเพียงตัวเดียว จะทำให้คอมพิวเตอร์สามารถทำงานได้ปริมาณงานที่มากขึ้นกว่าการที่ให้ซีพียูทำงานให้เสร็จทีละงาน
หลักความต้องการพื้นฐาน
- จุดประสงค์ของการรันโปรแกรมหลายโปรแกรมคือ ความต้องการที่จะให้ซีพียูมีการทำงานตลอดเวลา เพื่อให้มีการใช้ซีพียูอย่างเต็มที่ และเต็มประสิทธิภาพ
- สำหรับระบบคอมพิวเตอร์ที่มีซีพียูตัวเดียว ในเวลาใดเวลาหนึ่งซีพียูจะทำงานได้เพียงงานเดียวเท่านั้น ถ้ามีหลายโปรแกรมหรือหลายงาน งานที่เหลือก็ต้องคอยจนกว่าจะมีการจัดการให้เข้าไปใช้ซีพียู
- หลักการของการทำงานกับหลายโปรแกรมในขั้นพื้นฐานนั้นค่อนข้างจะไม่ซับซ้อน แต่ละโปรแกรมจะถูกรันจนกระทั่งถึงจุดที่มันต้องคอยอะไรซักอย่างเพื่อใช้ในการทำงานช่วงต่อไป ส่วนมากการคอยเหล่านี้เกี่ยวข้องกับอินพุต/เอาต์พุตนั่นเอง
- ซีพียูจะหยุดการทำงานในระหว่างที่คอยอินพุต/เอาต์พุตนี้ ซึ่งการคอยเหล่านี้เป็นการเสียเวลาโดยเปล่าประโยชน์ เพราะซีพียูไม่ได้ทำงานเลย
ตัวจัดการเวลาซีพียู (CPU Scheduler)
ตัวจัดการเวลาช่วงสั้น (short–term scheduler) จะเลือกโปรเซสที่อยู่ในหน่วยความจำที่พร้อมในการเอ็กซิคิวต์ที่สุด เพื่อให้ครอบครองเวลาซีพียูและทรัพยากรที่เกี่ยวข้องกับโปรเซสนั้น
คิวของโปรเซสในหน่วยความจำนั้นไม่จำเป็นที่ต้องเป็นแบบใดแบบหนึ่ง อย่างไรก็ตามโปรเซสทุกโปรเซสที่พร้อมใช้ซีพียู จะต้องมีโอกาสได้เข้าครอบครองเวลาซีพียูไม่เวลาใดก็เวลาหนึ่ง
การเข้าและออกจากการครอบครองเวลาซีพียูแต่ละครั้ง จำเป็นต้องมีการเก็บข้อมูลไว้เสมอว่าเข้ามาทำอะไร ต่อไปจะทำอะไร การจัดคิวระยะสั้นมีดังนี้
1. First-Come, First-Served Scheduling : FCFS (มาถึงก่อนได้รับบริการก่อน)
วิธีนี้เป็นวิธีที่ง่ายที่สุดในการจัดลำดับการทำงานของ process บน CPU โดยใช้หลักเกณฑ์ง่าย ๆ ว่า process ไหนที่ร้องขอใช้งาน CPU และเข้ารออยู่ใน ready queue (process ที่อยู่ในหน่วยความจำหลัก) ก่อนก็จะได้รับสิทธ์ในการเข้าใช้งาน CPU ก่อน เมื่อ process แรกทำงานเสร็จ process ที่มาถึงในลำดับถัดไปก็จะได้สิทธ์ในการทำงานบน CPU เป็นลำดับถัดไป ตัวอย่างข้างล่าแสดงถึงลำดับการมาถึงของ process และ burst บอกเวลาที่ใช้ในการทำงานบน CPU ตามลำดับ
Process Burst
P1 24
P2 3
P3 3
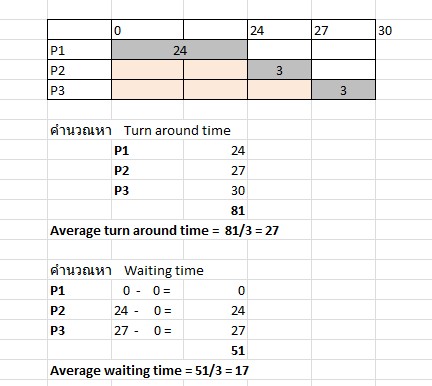
จากข้อมูลด้านบนเราสามารถคำนวณเวลาทั้งหมดที่ต้องใช้ไปเพื่อให้การทำงานของแต่ละ process เสร็จสมบูรณ์ (turn around time) และเวลาที่ใช้ในการรอของแต่ละ process (waiting time)ได้ดังนี้
จากในรูปเวลาเฉลี่ยที่ต้องในการทำงานให้เสร็จสิ้นของ process ทั้งหมดคือ 27 และเวลาเฉลี่ยที่ต้องใช้ในการรอของ process ทั้งหมดคือ 17 ข้อเสียของวิธีนี้ก็คือ เวลาที่จะต้องรอคอยในการเข้าทำงานบน CPU ของ process ที่มาถึงในลำดับท้าย ๆ นั้นจะนานมาก และเวลาเฉลี่ยที่ต้องใช้ในการรอคอยก็สูงมากเช่นเดียวกัน FCFS จึงไม่เหมาะกับระบบที่เป็น time-sharing พึงสังเกตุว่า FCFS เป็นการจัดลำดับการทำงานแบบ nonpreemptive
2. Shortest-Job-First Scheduling : SJF ให้งานที่ใช้เวลาน้อยที่สุดได้ทำงานก่อน
วิธีนี้ ถ้ามี process ที่มาถึง ready queue พร้อม ๆ กัน จะต้องจัดให้ process ที่มีเวลาในการทำงานน้อยกว่าได้ทำงานก่อน แต่ถ้ามีสอง process ที่มีเวลาในการทำงานเท่ากัน จะใช้วิธี FCFS หรือให้สิทธิ์ process ที่มาถึงก่อนได้ทำงานก่อน ตัวอย่างข้างล่าแสดงถึงลำดับการมาถึงของ process และ burst บอกเวลาที่ใช้ในการทำงานบน CPU ตามลำดับ
Process Burst
P1 6
P2 8
P3 7
P4 3
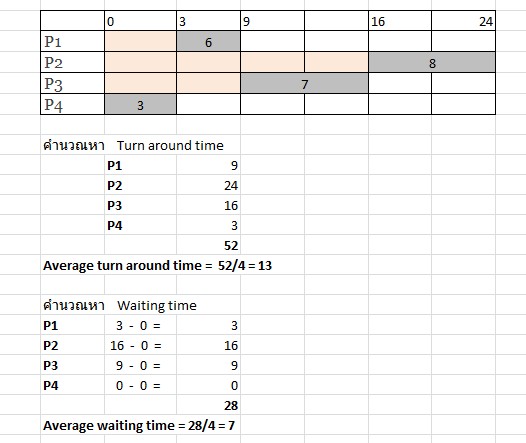
จากข้อมูลด้านบนเราสามารถคำนวณเวลาทั้งหมดที่ต้องใช้ไปเพื่อให้การทำงานของแต่ละ process เสร็จสมบูรณ์ (turn around time) และเวลาที่ใช้ในการรอของแต่ละ process (waiting time)ได้ดังนี้
ผลจากการคำนวณเวลาเฉลี่ยที่ต้องในการทำงานให้เสร็จสิ้นของ process ทั้งหมดคือ 13 และเวลาเฉลี่ยที่ต้องใช้ในการรอของ process ทั้งหมดคือ 7 ซึ่งจะเห็นได้ว่าวิธี SJF ใช้เวลาในการทำงานและเวลาในการรอน้อยกว่าวิธี FCFS มาก ความจริงแล้ว SJF น่าจะเป็นวิธีการจัดลำดับการทำงานที่ให้ผลที่ดีที่สุด แต่เป็นที่น่าเสียดายที่วิธี SJF ไม่สามารถนำมาใช้งานจริงได้ เนื่องจากเราไม่มีทางรู้ล่วงหน้าได้ว่าเวลาที่แต่ละ process จะใช้งาน CPU นั้นจริง ๆ แล้วมีค่าเท่าไหร่
วิธี SJF สามารถเป็นได้ทั้ง preemptive และ nonpreemptive ถ้าทุก process มาถึง ready queue พร้อม ๆ กัน ก็จะมีการทำงานเป็นแบบ nonpreemptive แต่ถ้า process มาถึงต่างเวลากัน process ที่มาถึงทีหลังแต่มีเวลาในการทำงานน้อยกว่า process ที่กำลังทำงานอยู่ในขณะนั้น สามารถเข้าแทรก หรือ preempt process ที่กำลังทำงานอยู่ได้ ดังตัวอย่่างต่อไปนี้
Process Arrival Time Burst Time
P1 0 8
P2 1 4
P3 2 9
P4 3 5
จะเห็นว่าเวลาที่มาถึงของแต่ละ process (arrival time) ไม่เท่ากัน เราสามารถคำนวณเวลาทั้งหมดที่ต้องใช้ไปเพื่อให้การทำงานของแต่ละ process เสร็จสมบูรณ์ (turn around time) และเวลาที่ใช้ในการรอของแต่ละ process (waiting time)ได้ดังนี้
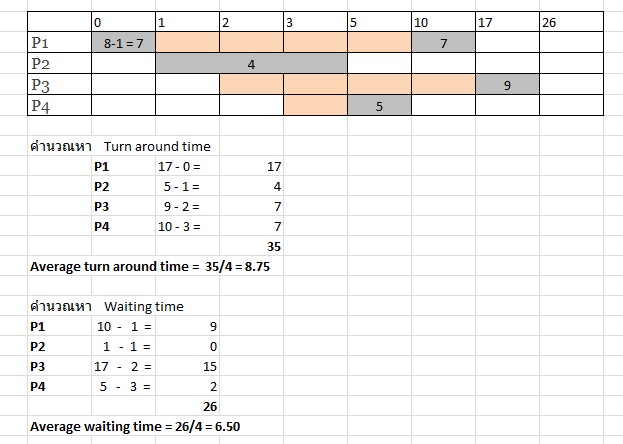 ผลการคำนวณสำหรับ SJF ที่มีการ
preemptive นั้น เวลาเฉลี่ยที่ต้องในการทำงานให้เสร็จสิ้นของ process
ทั้งหมดคือ 8.75 และเวลาเฉลี่ยที่ต้องใช้ในการรอของ process ทั้งหมดคือ
6.50
ผลการคำนวณสำหรับ SJF ที่มีการ
preemptive นั้น เวลาเฉลี่ยที่ต้องในการทำงานให้เสร็จสิ้นของ process
ทั้งหมดคือ 8.75 และเวลาเฉลี่ยที่ต้องใช้ในการรอของ process ทั้งหมดคือ
6.50
3. Priority Scheduling ให้ process ที่มีความสำคัญมากกว่าได้ทำงานก่อน
วิธีนี้จะต้องมีการกำหนดลำดับความสำคัญให้แก่ process ที่จะเข้ามาทำงานบน CPU ก่อนว่า process ใดความสำคัญมาก process ใดมีความสำคัญน้อย แล้ว CPU scheduler ก็จะจัดให้ process ที่มีความสำคัญมากที่สุดได้ทำงานก่อนและ process ที่มีความสำคัญน้อยกว่าได้เข้ามาทำงานต่อไปตามลำดับ ตัวอย่างข้างล่าแสดงถึง process ที่มาถึงพร้อมกัน เวลาในการทำงาน(burst) และระดับความสำคัญ (Priority) ที่ใช้ในการทำงานบน CPU ตามลำดับ
Process Burst Time Priority
P1 10 3
P2 1 1
P3 2 4
P4 1 5
P5 5 2
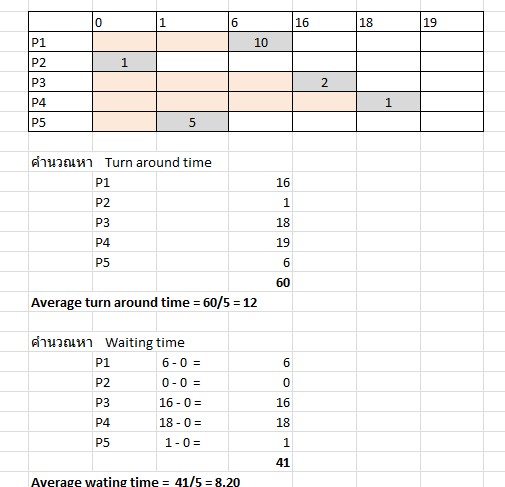
จะเห็นว่าแต่ละ process มี priority ที่ไม่เท่ากัน โดยตัวเลขที่ต่ำกว่าแสดงถึง priority ที่สูงกว่า (1 มี priority สูงสุดและ 5 มี priority ต่ำสุด) เราสามารถคำนวณเวลาทั้งหมดที่ต้องใช้ไปเพื่อให้การทำงานของแต่ละ process เสร็จสมบูรณ์ (turn around time) และเวลาที่ใช้ในการรอของแต่ละ process (waiting time)ได้ดังนี้
จะเห็นว่าแต่ละ process นอกจากมี priority ที่ไม่เท่ากันแล้ว
ยังมีเวลาที่มาถึง (arival) ไม่เท่ากันอีกด้วย
เราสามารถคำนวณเวลาทั้งหมดที่ต้องใช้ไปเพื่อให้การทำงานของแต่ละ process
เสร็จสมบูรณ์ (turn around time) และเวลาที่ใช้ในการรอของแต่ละ process
(waiting time)ได้ดังนี้
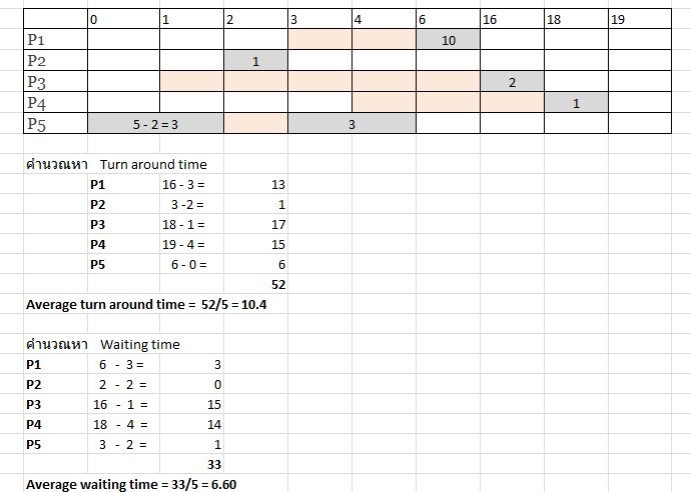
ผลการคำนวณสำหรับวิธี priority แบบที่ process เดินทางมาถึงไม่พร้อมกัน จะมีค่าเฉลี่ยของ turnaround time เท่ากับ 10.4 และค่าเฉลี่ยของ waiting time เท่ากับ 6.60
4.การจัดคิวแบบงานที่เหลือเวลาน้อยทำก่อน (Shortest-remaining-first : SRJ)
- วิธีการนี้จะคล้ายกับแบบ SJF แต่ SRJ จะนำเอาโปรเซสที่เหลือเวลาในการใช้ CPU น้อยที่สุดมาอยู่ที่ต้นคิวเพื่อเข้าไปใช้งาน CPU ก่อน
- วิธีการนี้จะทำให้ทั้งโปรเซสที่ต้องการเวลาในการใช้ CPU น้อย และโปรเซสที่ต้องการเวลาในการใช้ CPU มากแต่ใกล้จะจบสามารถออกจากระบบได้เร็วขึ้น
- วิธีการนี้นอกจากจะต้องทราบเวลาที่ต้องการใช้ CPU แล้วยังต้องมีการบันทึกเวลาที่โปรเซสทำงานไปแล้วด้วย
5.การจัดคิวแบบวนรอบ (Round-Robin : RR)
- เป็นวิธีการที่คิดขึ้นมาเพื่อใช้กับระบบงานคอมพิวเตอร์แบบแบ่งเวลาโดยเฉพาะ โดยมีลักษณะการจัดคิวเป็นแบบ FCFS แต่ให้มีกรรมวิธีของการให้สิทธิในการครอบครอง CPU ของแต่ละโปรเซส คือ “แต่ละโปรเซสที่เข้ามาในระบบจะถูกจำกัดเวลาการเข้าไปใช้ CPU เท่า ๆ กัน ”
ซึ่งเรียกช่วงเวลานี้ว่า เวลาควันตัม (Quantum Time)
- ตัวจัดเวลาระยะสั้นจะมีการให้ CPU กับโปรเซสที่อยู่ในคิวแบบวนรอบ โดยมีกฏเกณฑ์ว่า ถ้าโปรเซสใดไม่สามารถกระทำได้สำเร็จภายใน 1 ควันตัม โปรเซสจะต้องถูกนำกลับไปไว้ในคิวเช่นเดิม
- สถานภาพต่าง ๆ ของโปรเซสที่ยังทำไม่เสร็จจะถูกบันทึกไว้ เมื่อถึงโอกาสได้ครอบรอง CPU อีก ก็จะได้เริ่มต้นรันต่อจากครั้งที่แล้วโดยไม่ต้องเริ่มใหม่ทั้งหมด

6.การจัดคิวแบบหลายระดับ (Multilevel Queue Scheduling)
- การจัดคิวดังที่กล่าวมาแล้วทั้งสิ้นเป็นการจัดคิวภายในคิวเพียง 1 คิวเท่านั้น เรียกว่า
- การจัดคิวแบบ 1 ระดับดังรูปเพื่อให้การจัดคิวเป็นไปอย่างมีประสิทธิภาพมากขึ้น เราจึงจัดให้มีคิวหลาย ๆ คิวแทนที่จะมีเพียงคิวเดียว เรียกว่าเป็นการจัดคิวแบบหลายระดับ
- การจัดคิวแบบหลายระดับนั้น แต่ละคิวไม่จำเป็นเป็นต้องเป็นประเภทเดียวกัน
- การคัดเลือกโปรเซสนั้นจะคัดเลือกจากคิวที่ 1 ก่อนจนกระทั่งโปรเซสภายในคิวที่ 1 ทำงานเสร็จทั้งหมด แล้วจึงคัดเลือกโปรเซสในคิวลำดับถัดไป
- โปรเซสที่มีความสำคัญมาก มักจะอยู่ในคิวระดับแรก โปรเซสที่มีลำดับความสำคัญน้อยลงไปก็จะอยู่ในคิวระดับหลัง
- โปรเซสประเภทเดียวกันมักอยู่ในคิวระดับเดียวกัน

การจัดคิวระยะยาว (long-term scheduler)
- การจัดคิวระยะสั้นเป็นการจัดคิวในระดับโปรเซส โดยมีตัวจัดคิวระยะสั้นทำหน้าที่คัดเลือกโปรเซสที่อยู่ในคิวที่มีสถานะพร้อม ส่งเข้าไปอยู่ในสถานะรัน
- การจัดคิวระยะยาวเป็นการจัดคิวในระดับงาน ไม่ใช่ระดับโปรเซส
- เมื่อผู้ใช้ส่งงานเข้ามาในระบบ งานเหล่านี้จะไปรออยู่ในคิวงาน
- เมื่อระบบอยู่ในสภาพพร้อมที่จะรับโปรเซสใหม่ได้ เช่นมีหน่วยความจำเหลือมากพอ
- ตัวจัดคิวระยะยาวจะคัดเลือกงานที่อยู่ในคิวงานขึ้นมาพร้อมทั้งสร้างโปรเซสใหม่สำหรับงานนั้น ส่งให้กับตัวจัดคิวระยะสั้นทำงานต่อไป
- นอกจากนั้นตัวจัดคิวระยะสั้นยังมีหน้าที่ยุติโปรเซสที่จบการทำงานแล้วด้วย
- คิวงานจะต่างกับคิวของโปรเซสเล็กน้อย คือ งานที่ถูกคัดเลือกขึ้นมาและสร้างเป็นโปรเซสใหม่แล้วจะไม่มีการวนกลับมาเข้าคิวใหม่เหมือนกับโปรเซส
- การคัดเลือกงานเพื่อสร้างโปรเซสใหม่ มีวิธีการเหมือนกับการคัดเลือกโปรเซสที่อยู่ในคิว ยกเว้นวิธีแบบ RR ที่ไม่ได้ใช้กับคิวงาน

ระบบหลายโปรเซสเซอร์ (Multi-processor System)
- หมายถึงระบบที่มี CPU หลายตัวช่วยกันทำงาน
- ดังนั้นโปรเซสเซอร์ในที่นี้หมายถึง CPU นั่นเอง
- การจัดระบบคอมพิวเตอร์ตามการทำงานของโปรเซสเซอร์ เราสามารถแบ่งได้ 4 ประเภทดังนี้
- คำสั่งเดี่ยวและข้อมูลเดี่ยว ( Single Instruction Single Data : SISD )
- คำสั่งเดี่ยวและหลายชุดข้อมูล ( Single Instruction Multiple Data : SIMD )
- หลายชุดคำสั่งและข้อมูลเดี่ยว ( Multiple Instruction Single Data : MISD )
- หลายชุดคำสั่งและหลายชุดข้อมูล ( Multiple Instruction Multiple Data : SIMD )

คำสั่งเดี่ยวและข้อมูลเดี่ยว ( Single Instruction Single Data : SISD )
- คอมพิวเตอร์ที่ใช้งานทั่วไปในปัจจุบันจะเป็นประเภท SISD
- ระบบคอมพิวเตอร์ประเภทนี้มีโปรเซสเซอร์อยู่เพียงตัวเดียว
- การทำงานของโปรเซสเซอร์ในระบบนี้จะทำงานได้ทีละ 1 คำสั่งและรับข้อมูลได้ 1 ชุด
- P (Processor) แทนโปรเซสเซอร์ I (Instruction) แทนคำสั่ง D (Data) แทนข้อมูล และ O (Output) แทนผลลัพธ์
- การทำงานของระบบนี้เป็นการทำงานของโปรเซสเซอร์หลายตัวพร้อมกัน หรือที่เรียกว่าทำงานขนานกัน (parallel processing)
- โดยโปรเซสเซอร์ทุกตัวทำคำสั่งเดียวกันหมด แต่มีข้อมูลเป็นของตนเอง ดังนั้นผลลัพธ์ที่ได้จึงมีหลายชุด
- SIMD มีประโยชน์ต่องานทางด้านการคำนวณที่ต้องการคำนวณแบบเดียวกันกับข้อมูลหลาย ๆ ชุดเช่น การบวกเมตริกซ์

หลายชุดคำสั่งและข้อมูลเดี่ยว (Multiple Instruction Single Data : MISD )
- การทำงานของระบบนี้เป็นการทำงานของโปรเซสเซอร์หลายตัวพร้อมกัน หรือที่เรียกว่าทำงานขนานกัน (parallel processing)
- โดยโปรเซสเซอร์ทุกตัวจะมีคำสั่งของตนเอง แต่ทุกตัวจะใช้ข้อมูลชุดเดียวกัน
- เมื่อโปรเซสเซอร์ตัวแรกทำงานเสร็จ ผลลัพธ์ที่ได้จะเป็นข้อมูลของโปรเซสเซอร์ตัวต่อไป
- เช่นถ้าในระบบ MISD หาค่าจากสมการนี้ y = 2*X2+4 โดยที่ x มีค่าระหว่าง 1 ถึง 5
- จากตัวอย่างพบว่ามี 3 คำสั่ง
- หาค่า X ยกกำลัง 2
- คูณผลลัพธ์จากข้อแรก ด้วย 2
- เพิ่มค่าผลลัพธ์ที่ได้จากข้อ 2 ด้วย 4
- สมมุติว่าแต่ละคำสั่งใช้เวลาคำสั่งละ 1 วินาที
- ถ้าเป็นระบบ SISD จะใช้เวลาทั้งสิ้นเท่าใด ถ้าเป็นระบบ MISD จะใช้เวลาทั้งสิ้นเท่าใด
- การทำงานของระบบนี้เป็นการทำงานของโปรเซสเซอร์หลายตัวพร้อมกันและโปรเซสเซอร์แต่ละตัวจะมีคำสั่งและข้อมูลเป็นของตนเอง
- ดังนั้นในการทำงานแต่ละโปรเซสเซอร์จะเป็นอิสระจากกัน
- ตัวอย่างระบบคอมพิวเตอร์ประเภท MIMD ที่เห็นได้ชัดเจนคือระบบเครือข่ายคอมพิวเตอร์ (Computer Network)

แหล่งที่มาของข้อมูล
โดย นายอาทิตย์ ยลระบิล ชั้น ปวส.1 6031280069
การจัดเวลาซีพียู (CPU Scheduling)
การจัดเวลาซีพียู (CPU Scheduling) เป็นหลักการทำงานหนึ่งของโปรแกรมจัดการระบบที่มีความสามารถในการรันโปรแกรมหลาย ๆ โปรแกรมในเวลาเดียวกัน ซึ่งการแบ่งเวลาการเข้าใช้ซีพียูให้กับงานที่อาจถูกส่งเข้ามาหลาย ๆ งานพร้อม ๆ กัน ที่ซีพียูอาจมีจำนวนน้อยกว่าจำนวนโปรแกรม หรืออาจมีซีพียูเพียงตัวเดียว จะทำให้คอมพิวเตอร์สามารถทำงานได้ปริมาณงานที่มากขึ้นกว่าการที่ให้ซีพียูทำงานให้เสร็จทีละงาน
หลักความต้องการพื้นฐาน
- จุดประสงค์ของการรันโปรแกรมหลายโปรแกรมคือ ความต้องการที่จะให้ซีพียูมีการทำงานตลอดเวลา เพื่อให้มีการใช้ซีพียูอย่างเต็มที่ และเต็มประสิทธิภาพ
- สำหรับระบบคอมพิวเตอร์ที่มีซีพียูตัวเดียว ในเวลาใดเวลาหนึ่งซีพียูจะทำงานได้เพียงงานเดียวเท่านั้น ถ้ามีหลายโปรแกรมหรือหลายงาน งานที่เหลือก็ต้องคอยจนกว่าจะมีการจัดการให้เข้าไปใช้ซีพียู
- หลักการของการทำงานกับหลายโปรแกรมในขั้นพื้นฐานนั้นค่อนข้างจะไม่ซับซ้อน แต่ละโปรแกรมจะถูกรันจนกระทั่งถึงจุดที่มันต้องคอยอะไรซักอย่างเพื่อใช้ในการทำงานช่วงต่อไป ส่วนมากการคอยเหล่านี้เกี่ยวข้องกับอินพุต/เอาต์พุตนั่นเอง
- ซีพียูจะหยุดการทำงานในระหว่างที่คอยอินพุต/เอาต์พุตนี้ ซึ่งการคอยเหล่านี้เป็นการเสียเวลาโดยเปล่าประโยชน์ เพราะซีพียูไม่ได้ทำงานเลย
ตัวจัดการเวลาซีพียู (CPU Scheduler)
ตัวจัดการเวลาช่วงสั้น (short–term scheduler) จะเลือกโปรเซสที่อยู่ในหน่วยความจำที่พร้อมในการเอ็กซิคิวต์ที่สุด เพื่อให้ครอบครองเวลาซีพียูและทรัพยากรที่เกี่ยวข้องกับโปรเซสนั้น
คิวของโปรเซสในหน่วยความจำนั้นไม่จำเป็นที่ต้องเป็นแบบใดแบบหนึ่ง อย่างไรก็ตามโปรเซสทุกโปรเซสที่พร้อมใช้ซีพียู จะต้องมีโอกาสได้เข้าครอบครองเวลาซีพียูไม่เวลาใดก็เวลาหนึ่ง
การเข้าและออกจากการครอบครองเวลาซีพียูแต่ละครั้ง จำเป็นต้องมีการเก็บข้อมูลไว้เสมอว่าเข้ามาทำอะไร ต่อไปจะทำอะไร การจัดคิวระยะสั้นมีดังนี้
1. First-Come, First-Served Scheduling : FCFS (มาถึงก่อนได้รับบริการก่อน)
วิธีนี้เป็นวิธีที่ง่ายที่สุดในการจัดลำดับการทำงานของ process บน CPU โดยใช้หลักเกณฑ์ง่าย ๆ ว่า process ไหนที่ร้องขอใช้งาน CPU และเข้ารออยู่ใน ready queue (process ที่อยู่ในหน่วยความจำหลัก) ก่อนก็จะได้รับสิทธ์ในการเข้าใช้งาน CPU ก่อน เมื่อ process แรกทำงานเสร็จ process ที่มาถึงในลำดับถัดไปก็จะได้สิทธ์ในการทำงานบน CPU เป็นลำดับถัดไป ตัวอย่างข้างล่าแสดงถึงลำดับการมาถึงของ process และ burst บอกเวลาที่ใช้ในการทำงานบน CPU ตามลำดับ
Process Burst
P1 24
P2 3
P3 3
จากข้อมูลด้านบนเราสามารถคำนวณเวลาทั้งหมดที่ต้องใช้ไปเพื่อให้การทำงานของแต่ละ process เสร็จสมบูรณ์ (turn around time) และเวลาที่ใช้ในการรอของแต่ละ process (waiting time)ได้ดังนี้
จากในรูปเวลาเฉลี่ยที่ต้องในการทำงานให้เสร็จสิ้นของ process ทั้งหมดคือ 27 และเวลาเฉลี่ยที่ต้องใช้ในการรอของ process ทั้งหมดคือ 17 ข้อเสียของวิธีนี้ก็คือ เวลาที่จะต้องรอคอยในการเข้าทำงานบน CPU ของ process ที่มาถึงในลำดับท้าย ๆ นั้นจะนานมาก และเวลาเฉลี่ยที่ต้องใช้ในการรอคอยก็สูงมากเช่นเดียวกัน FCFS จึงไม่เหมาะกับระบบที่เป็น time-sharing พึงสังเกตุว่า FCFS เป็นการจัดลำดับการทำงานแบบ nonpreemptive
2. Shortest-Job-First Scheduling : SJF ให้งานที่ใช้เวลาน้อยที่สุดได้ทำงานก่อน
วิธีนี้ ถ้ามี process ที่มาถึง ready queue พร้อม ๆ กัน จะต้องจัดให้ process ที่มีเวลาในการทำงานน้อยกว่าได้ทำงานก่อน แต่ถ้ามีสอง process ที่มีเวลาในการทำงานเท่ากัน จะใช้วิธี FCFS หรือให้สิทธิ์ process ที่มาถึงก่อนได้ทำงานก่อน ตัวอย่างข้างล่าแสดงถึงลำดับการมาถึงของ process และ burst บอกเวลาที่ใช้ในการทำงานบน CPU ตามลำดับ
Process Burst
P1 6
P2 8
P3 7
P4 3
จากข้อมูลด้านบนเราสามารถคำนวณเวลาทั้งหมดที่ต้องใช้ไปเพื่อให้การทำงานของแต่ละ process เสร็จสมบูรณ์ (turn around time) และเวลาที่ใช้ในการรอของแต่ละ process (waiting time)ได้ดังนี้
ผลจากการคำนวณเวลาเฉลี่ยที่ต้องในการทำงานให้เสร็จสิ้นของ process ทั้งหมดคือ 13 และเวลาเฉลี่ยที่ต้องใช้ในการรอของ process ทั้งหมดคือ 7 ซึ่งจะเห็นได้ว่าวิธี SJF ใช้เวลาในการทำงานและเวลาในการรอน้อยกว่าวิธี FCFS มาก ความจริงแล้ว SJF น่าจะเป็นวิธีการจัดลำดับการทำงานที่ให้ผลที่ดีที่สุด แต่เป็นที่น่าเสียดายที่วิธี SJF ไม่สามารถนำมาใช้งานจริงได้ เนื่องจากเราไม่มีทางรู้ล่วงหน้าได้ว่าเวลาที่แต่ละ process จะใช้งาน CPU นั้นจริง ๆ แล้วมีค่าเท่าไหร่
วิธี SJF สามารถเป็นได้ทั้ง preemptive และ nonpreemptive ถ้าทุก process มาถึง ready queue พร้อม ๆ กัน ก็จะมีการทำงานเป็นแบบ nonpreemptive แต่ถ้า process มาถึงต่างเวลากัน process ที่มาถึงทีหลังแต่มีเวลาในการทำงานน้อยกว่า process ที่กำลังทำงานอยู่ในขณะนั้น สามารถเข้าแทรก หรือ preempt process ที่กำลังทำงานอยู่ได้ ดังตัวอย่่างต่อไปนี้
Process Arrival Time Burst Time
P1 0 8
P2 1 4
P3 2 9
P4 3 5
จะเห็นว่าเวลาที่มาถึงของแต่ละ process (arrival time) ไม่เท่ากัน เราสามารถคำนวณเวลาทั้งหมดที่ต้องใช้ไปเพื่อให้การทำงานของแต่ละ process เสร็จสมบูรณ์ (turn around time) และเวลาที่ใช้ในการรอของแต่ละ process (waiting time)ได้ดังนี้
3. Priority Scheduling ให้ process ที่มีความสำคัญมากกว่าได้ทำงานก่อน
วิธีนี้จะต้องมีการกำหนดลำดับความสำคัญให้แก่ process ที่จะเข้ามาทำงานบน CPU ก่อนว่า process ใดความสำคัญมาก process ใดมีความสำคัญน้อย แล้ว CPU scheduler ก็จะจัดให้ process ที่มีความสำคัญมากที่สุดได้ทำงานก่อนและ process ที่มีความสำคัญน้อยกว่าได้เข้ามาทำงานต่อไปตามลำดับ ตัวอย่างข้างล่าแสดงถึง process ที่มาถึงพร้อมกัน เวลาในการทำงาน(burst) และระดับความสำคัญ (Priority) ที่ใช้ในการทำงานบน CPU ตามลำดับ
Process Burst Time Priority
P1 10 3
P2 1 1
P3 2 4
P4 1 5
P5 5 2
จะเห็นว่าแต่ละ process มี priority ที่ไม่เท่ากัน โดยตัวเลขที่ต่ำกว่าแสดงถึง priority ที่สูงกว่า (1 มี priority สูงสุดและ 5 มี priority ต่ำสุด) เราสามารถคำนวณเวลาทั้งหมดที่ต้องใช้ไปเพื่อให้การทำงานของแต่ละ process เสร็จสมบูรณ์ (turn around time) และเวลาที่ใช้ในการรอของแต่ละ process (waiting time)ได้ดังนี้
ผลการคำนวณสำหรับวิธี
priority จะมีค่าเฉลี่ยของ turnaround time เท่ากับ 12 และค่าเฉลี่ยของ
waiting time เท่ากับ 8.20 วิธี priority สามารถเป็นได้ทั้งแบบ preemptive
และ nonpreemptive ถ้าทุก process มาถึง ready queue พร้อม ๆ กัน
ก็จะมีการทำงานเป็นแบบ nonpreemptive ตามตัวอย่างข้างบน แต่ถ้า process
มาถึงต่างเวลากัน process ที่มาถึงทีหลังแต่มี priorityในการทำงานสูงกว่า
process ที่กำลังทำงานอยู่ในขณะนั้น สามารถเข้าแทรก หรือ preempt process
ที่กำลังทำงานอยู่ได้ ดังตัวอย่่างต่อไปนี้
| Process | Arrival | Burst | Priority |
| P1 | 3 | 10 | 3 |
| P2 | 2 | 1 | 1 |
| P3 | 1 | 2 | 4 |
| P4 | 4 | 1 | 5 |
| P5 | 0 | 5 | 2 |
ผลการคำนวณสำหรับวิธี priority แบบที่ process เดินทางมาถึงไม่พร้อมกัน จะมีค่าเฉลี่ยของ turnaround time เท่ากับ 10.4 และค่าเฉลี่ยของ waiting time เท่ากับ 6.60
4.การจัดคิวแบบงานที่เหลือเวลาน้อยทำก่อน (Shortest-remaining-first : SRJ)
- วิธีการนี้จะคล้ายกับแบบ SJF แต่ SRJ จะนำเอาโปรเซสที่เหลือเวลาในการใช้ CPU น้อยที่สุดมาอยู่ที่ต้นคิวเพื่อเข้าไปใช้งาน CPU ก่อน
- วิธีการนี้จะทำให้ทั้งโปรเซสที่ต้องการเวลาในการใช้ CPU น้อย และโปรเซสที่ต้องการเวลาในการใช้ CPU มากแต่ใกล้จะจบสามารถออกจากระบบได้เร็วขึ้น
- วิธีการนี้นอกจากจะต้องทราบเวลาที่ต้องการใช้ CPU แล้วยังต้องมีการบันทึกเวลาที่โปรเซสทำงานไปแล้วด้วย
5.การจัดคิวแบบวนรอบ (Round-Robin : RR)
- เป็นวิธีการที่คิดขึ้นมาเพื่อใช้กับระบบงานคอมพิวเตอร์แบบแบ่งเวลาโดยเฉพาะ โดยมีลักษณะการจัดคิวเป็นแบบ FCFS แต่ให้มีกรรมวิธีของการให้สิทธิในการครอบครอง CPU ของแต่ละโปรเซส คือ “แต่ละโปรเซสที่เข้ามาในระบบจะถูกจำกัดเวลาการเข้าไปใช้ CPU เท่า ๆ กัน ”
ซึ่งเรียกช่วงเวลานี้ว่า เวลาควันตัม (Quantum Time)
- ตัวจัดเวลาระยะสั้นจะมีการให้ CPU กับโปรเซสที่อยู่ในคิวแบบวนรอบ โดยมีกฏเกณฑ์ว่า ถ้าโปรเซสใดไม่สามารถกระทำได้สำเร็จภายใน 1 ควันตัม โปรเซสจะต้องถูกนำกลับไปไว้ในคิวเช่นเดิม
- สถานภาพต่าง ๆ ของโปรเซสที่ยังทำไม่เสร็จจะถูกบันทึกไว้ เมื่อถึงโอกาสได้ครอบรอง CPU อีก ก็จะได้เริ่มต้นรันต่อจากครั้งที่แล้วโดยไม่ต้องเริ่มใหม่ทั้งหมด

6.การจัดคิวแบบหลายระดับ (Multilevel Queue Scheduling)
- การจัดคิวดังที่กล่าวมาแล้วทั้งสิ้นเป็นการจัดคิวภายในคิวเพียง 1 คิวเท่านั้น เรียกว่า
- การจัดคิวแบบ 1 ระดับดังรูปเพื่อให้การจัดคิวเป็นไปอย่างมีประสิทธิภาพมากขึ้น เราจึงจัดให้มีคิวหลาย ๆ คิวแทนที่จะมีเพียงคิวเดียว เรียกว่าเป็นการจัดคิวแบบหลายระดับ
- การจัดคิวแบบหลายระดับนั้น แต่ละคิวไม่จำเป็นเป็นต้องเป็นประเภทเดียวกัน
- การคัดเลือกโปรเซสนั้นจะคัดเลือกจากคิวที่ 1 ก่อนจนกระทั่งโปรเซสภายในคิวที่ 1 ทำงานเสร็จทั้งหมด แล้วจึงคัดเลือกโปรเซสในคิวลำดับถัดไป
- โปรเซสที่มีความสำคัญมาก มักจะอยู่ในคิวระดับแรก โปรเซสที่มีลำดับความสำคัญน้อยลงไปก็จะอยู่ในคิวระดับหลัง
- โปรเซสประเภทเดียวกันมักอยู่ในคิวระดับเดียวกัน

การจัดคิวระยะยาว (long-term scheduler)
- การจัดคิวระยะสั้นเป็นการจัดคิวในระดับโปรเซส โดยมีตัวจัดคิวระยะสั้นทำหน้าที่คัดเลือกโปรเซสที่อยู่ในคิวที่มีสถานะพร้อม ส่งเข้าไปอยู่ในสถานะรัน
- การจัดคิวระยะยาวเป็นการจัดคิวในระดับงาน ไม่ใช่ระดับโปรเซส
- เมื่อผู้ใช้ส่งงานเข้ามาในระบบ งานเหล่านี้จะไปรออยู่ในคิวงาน
- เมื่อระบบอยู่ในสภาพพร้อมที่จะรับโปรเซสใหม่ได้ เช่นมีหน่วยความจำเหลือมากพอ
- ตัวจัดคิวระยะยาวจะคัดเลือกงานที่อยู่ในคิวงานขึ้นมาพร้อมทั้งสร้างโปรเซสใหม่สำหรับงานนั้น ส่งให้กับตัวจัดคิวระยะสั้นทำงานต่อไป
- นอกจากนั้นตัวจัดคิวระยะสั้นยังมีหน้าที่ยุติโปรเซสที่จบการทำงานแล้วด้วย
- คิวงานจะต่างกับคิวของโปรเซสเล็กน้อย คือ งานที่ถูกคัดเลือกขึ้นมาและสร้างเป็นโปรเซสใหม่แล้วจะไม่มีการวนกลับมาเข้าคิวใหม่เหมือนกับโปรเซส
- การคัดเลือกงานเพื่อสร้างโปรเซสใหม่ มีวิธีการเหมือนกับการคัดเลือกโปรเซสที่อยู่ในคิว ยกเว้นวิธีแบบ RR ที่ไม่ได้ใช้กับคิวงาน

ระบบหลายโปรเซสเซอร์ (Multi-processor System)
- หมายถึงระบบที่มี CPU หลายตัวช่วยกันทำงาน
- ดังนั้นโปรเซสเซอร์ในที่นี้หมายถึง CPU นั่นเอง
- การจัดระบบคอมพิวเตอร์ตามการทำงานของโปรเซสเซอร์ เราสามารถแบ่งได้ 4 ประเภทดังนี้
- คำสั่งเดี่ยวและข้อมูลเดี่ยว ( Single Instruction Single Data : SISD )
- คำสั่งเดี่ยวและหลายชุดข้อมูล ( Single Instruction Multiple Data : SIMD )
- หลายชุดคำสั่งและข้อมูลเดี่ยว ( Multiple Instruction Single Data : MISD )
- หลายชุดคำสั่งและหลายชุดข้อมูล ( Multiple Instruction Multiple Data : SIMD )

คำสั่งเดี่ยวและข้อมูลเดี่ยว ( Single Instruction Single Data : SISD )
- คอมพิวเตอร์ที่ใช้งานทั่วไปในปัจจุบันจะเป็นประเภท SISD
- ระบบคอมพิวเตอร์ประเภทนี้มีโปรเซสเซอร์อยู่เพียงตัวเดียว
- การทำงานของโปรเซสเซอร์ในระบบนี้จะทำงานได้ทีละ 1 คำสั่งและรับข้อมูลได้ 1 ชุด
- P (Processor) แทนโปรเซสเซอร์ I (Instruction) แทนคำสั่ง D (Data) แทนข้อมูล และ O (Output) แทนผลลัพธ์
- การทำงานของระบบนี้เป็นการทำงานของโปรเซสเซอร์หลายตัวพร้อมกัน หรือที่เรียกว่าทำงานขนานกัน (parallel processing)
- โดยโปรเซสเซอร์ทุกตัวทำคำสั่งเดียวกันหมด แต่มีข้อมูลเป็นของตนเอง ดังนั้นผลลัพธ์ที่ได้จึงมีหลายชุด
- SIMD มีประโยชน์ต่องานทางด้านการคำนวณที่ต้องการคำนวณแบบเดียวกันกับข้อมูลหลาย ๆ ชุดเช่น การบวกเมตริกซ์

หลายชุดคำสั่งและข้อมูลเดี่ยว (Multiple Instruction Single Data : MISD )
- การทำงานของระบบนี้เป็นการทำงานของโปรเซสเซอร์หลายตัวพร้อมกัน หรือที่เรียกว่าทำงานขนานกัน (parallel processing)
- โดยโปรเซสเซอร์ทุกตัวจะมีคำสั่งของตนเอง แต่ทุกตัวจะใช้ข้อมูลชุดเดียวกัน
- เมื่อโปรเซสเซอร์ตัวแรกทำงานเสร็จ ผลลัพธ์ที่ได้จะเป็นข้อมูลของโปรเซสเซอร์ตัวต่อไป
- เช่นถ้าในระบบ MISD หาค่าจากสมการนี้ y = 2*X2+4 โดยที่ x มีค่าระหว่าง 1 ถึง 5
- จากตัวอย่างพบว่ามี 3 คำสั่ง
- หาค่า X ยกกำลัง 2
- คูณผลลัพธ์จากข้อแรก ด้วย 2
- เพิ่มค่าผลลัพธ์ที่ได้จากข้อ 2 ด้วย 4
- สมมุติว่าแต่ละคำสั่งใช้เวลาคำสั่งละ 1 วินาที
- ถ้าเป็นระบบ SISD จะใช้เวลาทั้งสิ้นเท่าใด ถ้าเป็นระบบ MISD จะใช้เวลาทั้งสิ้นเท่าใด
- การทำงานของระบบนี้เป็นการทำงานของโปรเซสเซอร์หลายตัวพร้อมกันและโปรเซสเซอร์แต่ละตัวจะมีคำสั่งและข้อมูลเป็นของตนเอง
- ดังนั้นในการทำงานแต่ละโปรเซสเซอร์จะเป็นอิสระจากกัน
- ตัวอย่างระบบคอมพิวเตอร์ประเภท MIMD ที่เห็นได้ชัดเจนคือระบบเครือข่ายคอมพิวเตอร์ (Computer Network)

แหล่งที่มาของข้อมูล
- https://msit5.wordpress.com/2013/09/10/scheduling-algorithms-%E0%B8%A7%E0%B8%B4%E0%B8%98%E0%B8%B5%E0%B8%88%E0%B8%B1%E0%B8%94%E0%B8%A5%E0%B8%B3%E0%B8%94%E0%B8%B1%E0%B8%9A%E0%B8%81%E0%B8%B2%E0%B8%A3%E0%B8%97%E0%B8%B3%E0%B8%87%E0%B8%B2/
- https://sites.google.com/site/patibatkran11/khorngsrang-khxng-rabb-ptibati-kar
- mathcom.uru.ac.th/~Kachane/OS/slide/OS_03_2.ppt

ความคิดเห็น
แสดงความคิดเห็น